Comparison between Data warehouse and Data Lake
In today's data age, data has become the most important resource for any organization. Businesses derive insights from the data which helps them in making sound business decisions. Extracting insights from big data requires a lot of resources. If the data is properly organized and the right set of tools have been utilized, an organization can save thousands of dollars per year.
When we talk about data organization and processing, we come across the terms Data Warehouse and Data Lake. I had some doubts earlier about these concepts. What the heck is a data lake? What is a data warehouse? For my use case should I go with a data warehouse like RedShift or set up my own data lake? What are the differences between the two? In any typical organization, both data lake and date warehouses are generally used.
What is a Data Lake?
Photo Credits: AWS
A data lake is a central repository of the data. The data could be of any type or structure
i.e., unstructured, semi-structured or structured. There are no scaling restrictions on the
size of the data stored in a Data Lake. There could be tens of processes which generate data
in different forms using different tools and stored at multiple different locations like MySQL DB,
DynamoDB or as files in a storage solution. Having data at different places makes it difficult for
others in the organization to know where, what data is stored?
Also, reading the data from multiple databases for analysis and reporting purposes could result in
performance bottlenecks.
Here comes the Data Lake to the rescue. We are able to collect data from various sources in a data lake. Cataloging the data present in the data lake is one of the most important components. Cataloging makes searching the data in the data lake easy, increasing the operational efficiency. A Data Lake can integrate with different compute frameworks like Map-Reduce, Spark, Presto, AWS Athena etc., helping resolving performance issues.
What is a Data warehouse?
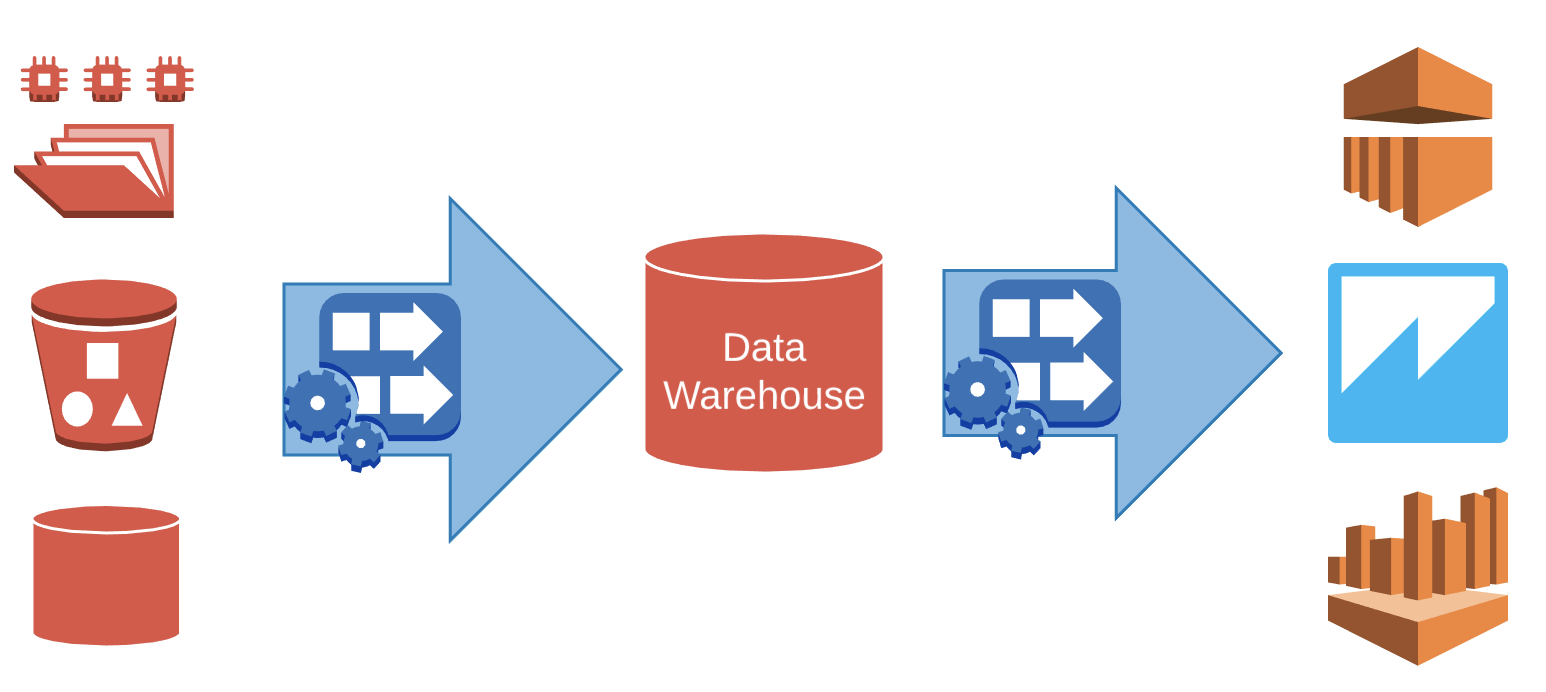
A data warehouse is a central repository of the structured data. It is designed to run query and analysis on historical data efficiently. Transactional data from various sources is ingested to a data warehouse. The data stored is non volatile i.e., older data is not omitted as new data is added. Also, the data in the data warehouse is subject oriented. Data warehouse contains the information to a specific subject like sales, not the whole data present in the organization.
Clearly, a data lake seems to be a superset of a data warehouse. The question arises what's the purpose of a data warehouse?
A data warehouse is commonly used for reporting and analytics as it stores structured and clean data. Data warehouses are optimized to perform analytics queries that lead to insights.
Let us compare Data Lake and Data warehouse with each other to understand what fits better for our use case.
Comparison between a Data warehouse and a Data Lake
| Data Lake | Data warehouse |
|---|---|
| Data Lake can store data regardless of its structure | Data has to be structured |
| Can store raw unprocessed and processed data | Stores processed, clean data |
| Schema-on-read architecture, allows writing any data as schema is not verified during write time. | Schema-on-write architecture. Reject the data not as per the schema. |
| Flexible: Allows using right compute framework and programming language for the job. | Queries have to be written in SQL only. |
| Can be used for any purpose. | Optimized for reporting an analytics use case. |
Hope, this post helps you in understanding the difference and similarity between the data warehouse and the data lake. Although, both are used to store the data in an organization but both serve the different purpose.
Remember, always choose the right tool for your use case.
That's it for today. Happy Learning!